Something very exciting happened this weekend – a team of amazing talented women and I entered the 25-hour Hack Manchester 2018 hackathon, and we won Best in Show.
I’ve moved the rest of this blog post over to my Medium blog.
If I can't find a simple explanation, I write notes for myself. Often about things related to software engineering.

Something very exciting happened this weekend – a team of amazing talented women and I entered the 25-hour Hack Manchester 2018 hackathon, and we won Best in Show.
I’ve moved the rest of this blog post over to my Medium blog.

If you have a simple .Net console app and you’d like to convert it into a .Net Core app so that you can run it from the command line on any platform (as long as you install .Net Core), here’s what to do:
See also the following post:

(I’ve learnt a lot more since I originally wrote this (for instance, how to debug your tests), so this is an updated version).
This weekend I was part of a team that took part in the annual Hack Manchester hackathon (and we won Best in Show! Yay!). We used .Net Core for our back end code, and we got stuck in the middle of the night trying to add tests to our solution. It turned out the solution was pretty simple, so I’m documenting it here.
A skeleton NUnit test:
using NUnit.Framework;
namespace KiwilandRouteApplication.Tests
{
[TestFixture]
public class DummyTests
{
[Test]
public void DemoTest()
{
Assert.True(true);
}
}
}
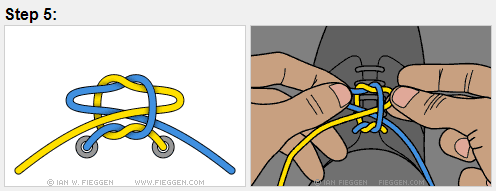
Now that I’ve actually taught my son to tie his shoelaces, I’ve updated the original post here with the method we found successful: https://insimpleterms.blog/2018/03/15/how-to-tie-your-shoelaces/

I couldn’t find anywhere all the Hack Manchester 2018 challenges / prizes were listed together, so I’m putting them all on one page for easy comparison.
! I’m not sure if they’re all there yet – there might be more to come, so keep an eye on the Hack Manchester site (scroll down to the “THE CHALLENGES” – yellow section just before the schedule).
Follow the links below to find out about the sponsors and see more detail / explanation about the challenges:
WebApp UK: Best in Show. (Our team came second for Best in Show last year. Just sayin’.)
MediaBurst: “The most bizarre use of ClockworkSMS!.”
Dunnhumby: “use data to make the consumer experience… less than optimal.”
Centre For Biological Timing: “make technology work for our body clocks rather than against them … hack your body clock!”
AND Digital: “Can clever tech help turn passenger misery into passenger delight?”


I was working with some Groovy scripts in IntelliJ today – a first for me. I came up against a couple of simple getting-started issues… I’m just making notes about them here. There are notes here on two errors I came across: “Unable to resolve class” and “Configure Groovy SDK”.
2. “Unable to resolve class”
More here: https://stackoverflow.com/questions/45072923/groovy-unable-to-resolve-class

The other day I posted this problem.
In the process of chatting about it, an associated mathematics problem came up, about permutations and probabilities.
To remind you of the basic problem: We have 450 conference attendees. We have one day of workshops. There are five sessions throughout the day, and five workshops to attend. We want every attendee to attend every workshop. The workshops are being repeated throughout the day: In every session, there are 10 rooms available. There are five workshops, and each workshop is duplicated. So for instance, workshop 1 will be run in rooms A and B, workshop 2 in rooms C and D, etc. They are repeated throughout the day, so one attendee might do them in the order 15423, and another might do 42315.
There will be 45 people in each workshop. The nub of the problem is that the organisers want as much cross-pollenation as possible. People do not get to choose what order they do the workshops: they are told which room to be in at what time. The organisers would like each attendee to meet as many new people as possible in every single session.
So here’s the maths question: What is the minimum average number of repeat people that attendees have to meet in each session? By “repeat people” I mean “people they have already attended a previous session with.”
There is one extra constraint: There is one group of 30 people (labelled “FRIENDS” in the spreadsheet below) that have to be kept together in every session. So they only get 15 people in every session that they may not have met before, ie for them the min value of Repeat People is 30 in every session. This also has an impact on all the other people in the other sessions.
However this is still an interesting problem even without the extra 30-people constraint.
So in session one, Repeat People = 0. In every one of the workshops in session 1, attendees are in a brand new group of people that they have never attended this conference with before.
So what is the minimum average value of Repeat People for session 2? I’m specifying average, because it would be possible to keep things pure for at least one attendee, where they meet 44 new people in every single session. But that would have an adverse effect on everyone else. So I’m aiming for everyone to have roughly the same number of Repeat People per workshop.
I have two theories, one of which I can prove:
Here is a way of visualising the problem:

I’ll be very interested to hear any solutions!

The problem is described here. You could approach the problem as a coding kata, which I’d love to do at some point – I didn’t have the time on this occasion. I ended up just solving it using pen and paper.
My solution is below. It won’t be the only solution, there are probably better ones out there that rely more on randomisation and less on patterns (or just use better patterns).
Don’t scroll down if you want to have a go at it yourself first!
…
…
So, I found a solution which works pretty well. I’m pretty pleased with it, and it’s nice and simple and neat.
The participants are split into groups of 15. The FRIENDS are in two groups of 15, both marked “FRIENDS” in the spreadsheet below. All the other groups are non-FRIENDS (well they might be friends, who knows? But they still don’t get to stay together – we’re mean like that).
It does mean that the people move in groups of 15, and they will stay in those groups. Not that they will necessarily know it. Because of the numbers, no matter what you do, they will keep encountering some people repeatedly (the maths of this is a separate problem which I’ve blogged about here). If you shuffle the list and assign the non-FRIENDS to 28 groups of 15, hopefully they will already be mixed up with people they don’t know, so they needn’t be aware that they have been grouped. I’ve labelled the groups B1 to O1 and B2 to O2.
What it does mean is that each group of 15 never encounters another group of 15 twice – they meet a different two groups in every session. So everybody meets 30 new people in every session (I haven’t actually proved this but I’m pretty confident).
(Since I came up with this, I’ve realised I can improve it quite a lot so that people don’t have to stay with exactly the same 15 people – scroll down to the bottom to see this improvement).
So, there are three groups in every session, like this (this is my actual solution):

Here’s how I did it:
First, split the non-FRIENDS people into two halves, 225 in each half. The first half has groups B1 to O1, and the second group has B2 to O2.
For now, we will also split the FRIENDS into two groups, A1 and A2 (this was my “Aha” moment, all made possible because of the fact that you have duplicate workshops in each session).
So for each half, we have letters A to O. For the first session, we just spread them across the 5 workshops: ABC in the workshop 1, DEF in workshop 2… etc.
For the second session, the first group in each triplet just shuffles along to the next workshop. So A is now in workshop 2, D is in workshop 3, etc.
We keep doing this all the way down the sessions, for the first group in each triplet.
For the second group in each triplet (B, E, H, K and N), instead of shuffling them on by 1, we shuffle them 2 workshops along. So, B was in workshop 1 in session 1, then we add 2 so they are workshop 3 for session 2, then add 2 again so they are in workshop 5 for session 3, keep going (wrapping around) and they are in workshop 2 for session 4 and workshop 4 for session 5. Do this for all the second groups (B, E, H, K and N).
For the third group in each triplet (C, F, I, L, O), add 3 on each time. So group C has the following workshops: 1, then 4, then 2, then 5, then 3.
Do this for all of those third groups.
This is what you get:
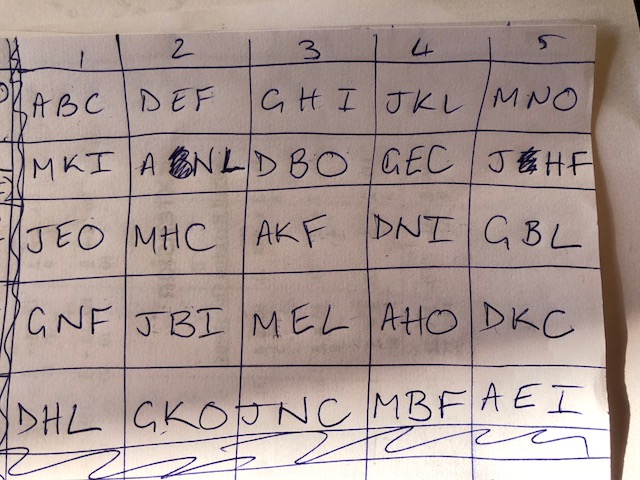
Now, at this point you have a problem: Your FRIENDS group have been split into two groups of 15. But ooh! Look! You did the same thing for A1 to O1 as you did for A2 to O2!
A1 and A2 are always in the same workshops at the same time. So you can move A2 into the same workshop as A1, and swap another group out into the spot left blank by A2.
I then renamed both A1 and A2 to “FRIENDS”, and that’s how I arrived at the spreadsheet pasted above.
Since I came up with this, I’ve realised I can improve it quite a lot so that people don’t have to stay with exactly the same 15 people:
The “FRIENDS” group mess it up a bit, but in most cases you’ll have parallel groups moving independently in duplicate workshops, eg when group C1 is doing workshop 3, group C2 will be doing the other duplicate of workshop 3.
Well… If each group of 15 was split into two sub groups of 7 and 8, then they could shuffle around and meet each other. Also this could be done dynamically.
So, for instance, you have C1a (7 people), C1b (8 people), C2a (7 people) and C2b (8 people).
In session 2, swap C1b and C2b so now only 7 (or 8) people stay together. Do the same with all groups (except those affected by the “FRIENDS” group).
In session 3, put C1a with C2a and C1b with C2b. This adds up to 14 and 16, so somebody will have to switch sub groups. In sessions 4 and 5 you could split them again, but this time randomly. As long as all the Cs are doing the same workshops, you can split them how you like. Ultimately they will all meet each other so they’ll still have repetition with 15 people overall, but it won’t be the same 15 people in every workshop. And they’ll still get 30 brand new people in every workshop.

I think this would make a great code kata, although I found a solution using pen and paper. It is a real problem, which my friend is genuinely trying to solve.
She is organising a conference. She has been given the following very interesting, and non-negotiable, requirements:
There will be one day of workshops. There are 5 sessions and 5 workshops. There will be 45 people in each workshop. There are 450 conference attendees, so each workshop is duplicated in each session. That is to say, during each session there will be ten actual workshops, but only five distinct workshops. So workshop 1 is happening simultaneously in two different rooms, as are the rest of them.
The aim is for participants to meet as many new people as possible. So for each attendee, we want to minimise the number of people in each workshop that they have met in a previous workshop.
We also want every attendee to attend every workshop.
And there is one more special requirement: There is a group of 30 attendees, we’ll call them FRIENDS, that must be kept together at all times. So in their workshops, there will be a rotating number of 15 extra people. They must meet a different 15 people in every workshop.
I have a solution for this, but I’ll post it separately in case you want to try it for yourself.
Here is a diagram that might help you to visualise the problem:
Here is my solution to the problem.
There is an associated maths problem about the permutations and probabilities involved, here.

tl;dr: The mathematical definition of an idempotent function is subtly different to the definition used in software engineering. In software engineering an idempotent function is one that has the same impact on state, no matter how many times it is run. In mathematics, an idempotent function is one where f(x) =f(f(x)).
The concept of idempotence came up recently at work, in the context of infrastructure. A statement along the lines of “When treating infrastructure as code, it’s often important to ensure that your functionality is idempotent.”
I asked what “idempotent” meant, and I was given the (incorrect in all contexts) answer, “for the same input, you will always get the same output.” I was also told (correct for maths, but not for software) that the following function is not idempotent:
f(x) = x + 1
…but the following function is idempotent:
f(x) = x * 1
This instantly got me asking questions, because the first two definitions I was given were at odds with one another. The first definition describes a deterministic function. For instance: Both f(x) = x + 1 and f(x) = x * 1 are deterministic, ie given the same input, you’ll always get the same output (3 + 1 will always be equal to 4, and 3 * 1 will always equal 3).
But then I was given a better example, more relevant to the original conversation: If you have a function that adds an entry to a hosts file, you want to know that no matter how many times you execute that function, you will only ever add one entry to the hosts file. You don’t want to add more than one entry.
For instance, we start with a hosts file that looks like this:
127.0.0.1 localhost
We run our function, and now it looks like this:
127.0.0.1 localhost
255.255.255.255 broadcasthost
We run our function again, and nothing changes. The broadcasthost entry has already been added. Our function has nothing to do.
And then I found a true (in mathematics) definition of idempotence:
A function f(x) is idempotent if f(x) = f(f(x)).
To reiterate: The originator made a mistake: It is NOT true that idempotence is defined as “the same input always gives the same output”.
That is to say, if a function is idempotent and you apply that function to x, then you apply the function again to the return value, you still get the same result. Keep taking the result of each pass and sending it back into the function, and you still get the same result.
At this point I didn’t know about the difference between mathematical idempotence and software idempotence, and I was happy with my new definition: In our hosts file example, if our function takes the file content as an input and outputs the transformed result as an output, you can keep reapplying the function and you will keep getting the same result.
Using our new definition, we can easily see how f(x) = x + 1 is not idempotent, but f(x) = x * 1 is idempotent.
So far so good. But then I found this article claiming that pure functions are always idempotent, and my head exploded.
A pure function is one that has no side effects and no hidden state. The example given was this one:
f(a,b) = a + b
My confusion stemmed from two sources: Firstly, how can I apply my definition above – f(x) = f(f(x)) to this new example? It takes two parameters, but only returns one result! But secondly, how can it possibly be idempotent? It’s deterministic, yes, but any way you can find of repeatedly applying the same function to a new output will surely produce a different result? And what on earth does its pureness have to do with anything??
Well. I asked a bunch of clever people, and discovered that I had been dealing with the mathematical definition of idempotence, which is subtly different to the software engineering definition.
In software engineering, it’s all about state. My hosts file example was flawed because I had assumed that the hosts file content was being passed in as an input and then returned as an output. In fact, we are talking about a function that acts on the hosts file. This function’s input may be the hosts file path. Its output may be some kind of success code. It is not a pure function, because it will have the side effect (sometimes) of altering the state of the hosts file.
BUT our idempotent hosts-file-editing function can be run several times, and its effect on state will always be the same. No matter how many times we run this function, the hosts file will always be impacted in the same way.
The article that confused me so much was in fact making a very simple point: Pure functions are idempotent because they do not alter state. Therefore state is always impacted in the same way by multiple calls to a pure function, because it is simply not impacted. So in reality, most idempotent functions are not pure, but all pure functions are idempotent.
One common example of idempotence in software engineering is the HTTP specification – which states that GET, PUT and DELETE requests should all be idempotent, but POST should not.
At this point I will quote my colleague Mouad (and the Stormpath blog), who between them say this:
“The HTTP RFC have a better definition which goes:
A request method is considered “idempotent” if the intended effect on the server of multiple identical requests with that method is the same as the effect for a single such request.
The ‘intended effect’ as defined above is not the same thing as the returned value, example: calling PUT two times may return a different result in the second call (e.g. 409 conflict), but a PUT is still idempotent if the state and effect didn’t change by the second call, in other words, ‘HTTP idempotency only applies to server state – not client state’ ref. https://stormpath.com/blog/put-or-post.”
Hopefully your head has not exploded. Or if it did, I manage to unexplode it and return it to its former state. Hopefully also, no matter how many more times you read this post, your head will remain unexploded. And we have ourselves an idempotent blog post. Voila!