
The problem is described here. You could approach the problem as a coding kata, which I’d love to do at some point – I didn’t have the time on this occasion. I ended up just solving it using pen and paper.
My solution is below. It won’t be the only solution, there are probably better ones out there that rely more on randomisation and less on patterns (or just use better patterns).
Don’t scroll down if you want to have a go at it yourself first!
…
…
So, I found a solution which works pretty well. I’m pretty pleased with it, and it’s nice and simple and neat.
The participants are split into groups of 15. The FRIENDS are in two groups of 15, both marked “FRIENDS” in the spreadsheet below. All the other groups are non-FRIENDS (well they might be friends, who knows? But they still don’t get to stay together – we’re mean like that).
It does mean that the people move in groups of 15, and they will stay in those groups. Not that they will necessarily know it. Because of the numbers, no matter what you do, they will keep encountering some people repeatedly (the maths of this is a separate problem which I’ve blogged about here). If you shuffle the list and assign the non-FRIENDS to 28 groups of 15, hopefully they will already be mixed up with people they don’t know, so they needn’t be aware that they have been grouped. I’ve labelled the groups B1 to O1 and B2 to O2.
What it does mean is that each group of 15 never encounters another group of 15 twice – they meet a different two groups in every session. So everybody meets 30 new people in every session (I haven’t actually proved this but I’m pretty confident).
(Since I came up with this, I’ve realised I can improve it quite a lot so that people don’t have to stay with exactly the same 15 people – scroll down to the bottom to see this improvement).
So, there are three groups in every session, like this (this is my actual solution):

Here’s how I did it:
First, split the non-FRIENDS people into two halves, 225 in each half. The first half has groups B1 to O1, and the second group has B2 to O2.
For now, we will also split the FRIENDS into two groups, A1 and A2 (this was my “Aha” moment, all made possible because of the fact that you have duplicate workshops in each session).
So for each half, we have letters A to O. For the first session, we just spread them across the 5 workshops: ABC in the workshop 1, DEF in workshop 2… etc.
For the second session, the first group in each triplet just shuffles along to the next workshop. So A is now in workshop 2, D is in workshop 3, etc.
We keep doing this all the way down the sessions, for the first group in each triplet.
For the second group in each triplet (B, E, H, K and N), instead of shuffling them on by 1, we shuffle them 2 workshops along. So, B was in workshop 1 in session 1, then we add 2 so they are workshop 3 for session 2, then add 2 again so they are in workshop 5 for session 3, keep going (wrapping around) and they are in workshop 2 for session 4 and workshop 4 for session 5. Do this for all the second groups (B, E, H, K and N).
For the third group in each triplet (C, F, I, L, O), add 3 on each time. So group C has the following workshops: 1, then 4, then 2, then 5, then 3.
Do this for all of those third groups.
This is what you get:
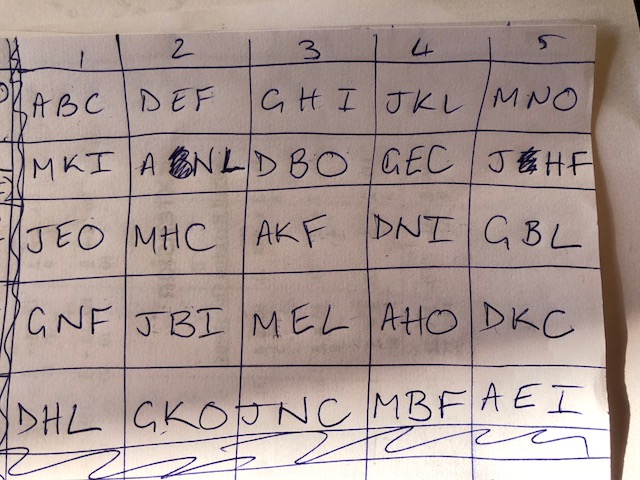
Now, at this point you have a problem: Your FRIENDS group have been split into two groups of 15. But ooh! Look! You did the same thing for A1 to O1 as you did for A2 to O2!
A1 and A2 are always in the same workshops at the same time. So you can move A2 into the same workshop as A1, and swap another group out into the spot left blank by A2.
I then renamed both A1 and A2 to “FRIENDS”, and that’s how I arrived at the spreadsheet pasted above.
POST SCRIPT (also see separate maths problem here):
Since I came up with this, I’ve realised I can improve it quite a lot so that people don’t have to stay with exactly the same 15 people:
The “FRIENDS” group mess it up a bit, but in most cases you’ll have parallel groups moving independently in duplicate workshops, eg when group C1 is doing workshop 3, group C2 will be doing the other duplicate of workshop 3.
Well… If each group of 15 was split into two sub groups of 7 and 8, then they could shuffle around and meet each other. Also this could be done dynamically.
So, for instance, you have C1a (7 people), C1b (8 people), C2a (7 people) and C2b (8 people).
In session 2, swap C1b and C2b so now only 7 (or 8) people stay together. Do the same with all groups (except those affected by the “FRIENDS” group).
In session 3, put C1a with C2a and C1b with C2b. This adds up to 14 and 16, so somebody will have to switch sub groups. In sessions 4 and 5 you could split them again, but this time randomly. As long as all the Cs are doing the same workshops, you can split them how you like. Ultimately they will all meet each other so they’ll still have repetition with 15 people overall, but it won’t be the same 15 people in every workshop. And they’ll still get 30 brand new people in every workshop.


