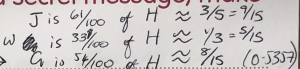I wrote this post recently about some idle maths I did while trying to doodle regular pentagons and pentagrams.
My parents (bothmathematicians) were immediately interested, and started trying to create pentagons on paper via origami.
We found thesevideos on YouTube and had fun making the apparent regular pentagon and pentagram, but discovered the maths was slightly out, and they weren’t quite regular. As my dad said, “The cosine of the double angle (that’s the first one you make) is 1/square root of 10, but it should be 1/4(root 5 – 1). So the actual angle, which should be 72 degrees, is … (gets out old Casio calculator, dusts it, Oh it’s dead, my phone’s not charged, where’s the calculator on my computer?) … oh, you do it. It would be right if the square root of 5 was 2.200 instead of 2.236.”
I had a dim memory that I was taught how to fold a pentagon from an A4 sheet when I was doing my maths teacher training. I went hunting in some folders in a corner of my study, and found this:
Start with a sheet of A4 and fold along the diagonal:
Now fold that in half along a vertical axis:
Now open it out again:
You now have a new slanted fold across the middle:
Fold along this new fold:
You’re now going to create two new folds on either side:
You’ll do this by bringing the edges into the centre:
Turn it over to get a slightly better view of the pentagon:
Whether this is really a regular pentagon, I don’t know, I haven’t tried to do the maths yet.
It’s an exercise for the reader!
Edit: Look away now if you want to work it out for yourself…
According to my dad, “No, that’s not a regular pentagon. The angle at the top has cosine —1/3 but it ought to be — (sqrt{5} — 1)/4. Close, but …”
Also Colin Wright (@ColinTheMathmo) spotted that “It’s very close, but the angle where the first corners are folded to meet is not 108 degrees.”
So if you want to make something that looks like a pentagon, the above solution is pretty neat.
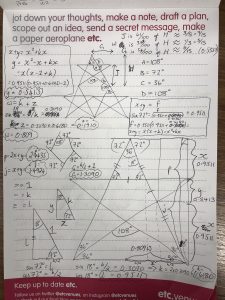
I was in a workshop the other day and I started a doodle which I often do (or some version of it) when I’m in meetings and such:
I Iove drawing pentagrams because they’re so satisfying – five quick lines is all you need, without lifting your pen from the paper.
But whenever I do this doodle, it always bothers me that these are not really pentagrams, and the contained shapes are not pentagons. I often wonder what would happen to the tesselation if I was drawing real pentagons. I also wonder how I could draw proper pentagrams without a protractor.
(For clarity, a pentagram is a five-pointed star. A pentagon is a five-sided shape. And when I say “real” I mean “regular” – ie shapes with rotational symmetry, where every point, every angle, every side is equal. And “tesselation” is a word that describes the way different shapes slot together side by side, with no gaps (I learnt that word in primary school, in relation to Roman mozaics):
).
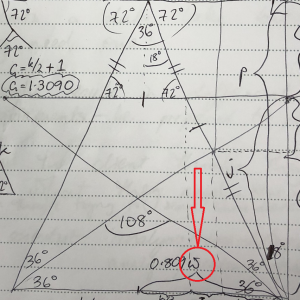
So during this workshop I did some trigonometry to work it all out. For those of you who were there with me, this is what I was scribbling in the breaks when I was being so antisocial:
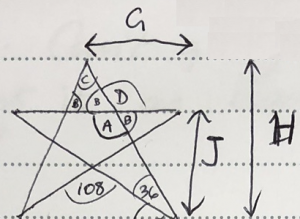
The conclusion I came to was that on lined paper, I could get a reasonable approximation of a pentagram using the following proportions:
If you’re wondering what w represents, I drew it on a different diagram when I realised that G and w were not the same distance – they only appeared to be because I was drawing non-regular pentagrams:
Based on these proportions and the dots that each horizontal line was made of, I came up with the following not-bad pentagrams (they’d probably be better if I had a ruler available instead of drawing freehand):
…and now the pentagons are all regular pentagons, and the pentagrams are regular too, but they’re forced to collide with each other as a result.
For the sake of aesthetics I think I prefer the non-regular versions at the top of this post, but the mathematician in me is now happy. 🙂
I got pinged by my colleague @j_f_green this morning with the following message: “Hey Clare. Hope all is well. Was wondering if I could be cheeky and get your input on a (small) thing I’m trying to solve? I am searching for an elegant solution and I’m starting to suspect the answer may involve maths.”
…and of course I was instantly interested.
The problem
It turned out to be a relatively simple problem, depending on your point of view. If I say “GCSE-level simultaneous equations” your reaction will tell you whether that’s simple for you or not (for people not in theUK, GCSEs are the exams our pupils take when they are 16 years old).
Here is the problem: We want to discover two whole numbers (aka positive integers) that will give us the height and width of a grid in cells, given the following constraints:
We have a number, let’s call it capacity, which represents the minimum number of cells to fill the grid. We want at least that many cells. We’re happy if we have more, but not if we have fewer.
We also have another number, we’ll call it aspectRatio, which is the aspect ratio of the grid. This is the relationship between height and width. So for instance, if the aspect ratio is 2:1, that means the width is twice the height (it’s twice as wide as it is high). To reduce that to a single number, aspectRatio is 2.
width = 2 * height = aspectRatio * height
(aspectRatio will often be a decimal or a fraction, so for instance if width is half height, aspectRatio is 0.5, or if the ratio is 2:3 then aspectRatio = 2/3 = 0.66, and width = 0.66 * height)
A concrete example
Here is a concrete example: Let’s say we have a grid that is twice as wide as it is high, so aspectRatio = 2. Let’s also say that our capacity is 200: We want to fit at least 200 cells into this space. I’ve deliberately chosen an easy example, and the answer in this case would be a width of 20 and a height of 10:
Apologies if that’s making your eyes hurt. Is it making your eyes hurt? It’s making my eyes hurt. I’ll try and make a better diagram later. It’s not even got the correct aspect ratio on the page…
If you enjoy attacking maths problems, look away now. Have a go at solving it before you read on. You may come up with a better solution anyway.
So how do we compute the answer?
One way would be a loop. Here is some code that would do the job:
var capacity = 1000;
var aspectRatio = 1000 / 800 = 1.25;
Here we have a grid that has at least 1000 cells:
36 * 29 = 1044
It has roughly the correct aspect ratio:
36 / 29 = 1.24
1000 / 800 = 1.25
The problem with this is that it does not scale well. The higher the numbers, the longer the loop. But fear not – maths to the rescue.
A simple use case
Let’s start with a simple use case: imagine the aspect ratio is 2:1, and the width is twice the height. Also let’s say we’re trying to fit 200 pixels into the space.
Let’s call width and height x and y. So:
x * y = 200
and
x = 2 * y = 2y
If x = 2y then x * y is the same as 2y * y, which is 2y²:
2y² = 200
y² = 100
y = 10
x = 20 (because it’s 2y)
A generalised solution
The first block above gives us our two simultaneous equations.
We can generalise the same approach for all numbers. Let’s call the capacity a, and the ratio b. Using our equations from above :
x * y = a
and
x = b * y
These are our simultaneous equations. Using the same logic as above, we substitute y for x and end up with:
by² = a
Which means that
y² = a/b
and
y = sqrt(a/b)
(where “sqrt” is square root).
Then once you’ve calculated y, you can calculate x:
x = b * y
The only missing piece of the puzzle is that we are dealing with inequality, not equality. So really it’s this:
y >= sqrt(a/b)
This just means that once you get a result, you round it up to the nearest integer. Same applies to the final substitution : if b * y is not a whole number, then round it up.
When you calculate b * y, you should use y BEFORE rounding.
So to finish, let’s stop being mathsy and start being softwarey. Let’s give our variables some meaningful names:
height >= sqrt(capacity / aspectRatio)
width = aspectRatio * height
If we test it with the example we used in the loop above, where aspectRatio = 1.25 and capacity = 1000, we get the same results:
Compared to the loop we started with, this scales brilliantly. It doesn’t matter how big the numbers are, the compute time is basically the same. It has a constant computational complexity, otherwise known as O(1)*. The solution above using a loop gets slower and slower depending on how big the numbers are. It has a computational complexity of O(n), so it’s not as good.
Hopefully that makes sense and I didn’t over-simplify. All feedback welcome.
* I couldn’t remember how to express O(1) so I initially guessed at O(k), because I was thinking of k as a constant. Sadly I was wrong, because I rather like the thumbs-up “Ok” concept.
In the process of chatting about it, an associated mathematics problem came up, about permutations and probabilities.
To remind you of the basic problem: We have 450 conference attendees. We have one day of workshops. There are five sessions throughout the day, and five workshops to attend. We want every attendee to attend every workshop. The workshops are being repeated throughout the day: In every session, there are 10 rooms available. There are five workshops, and each workshop is duplicated. So for instance, workshop 1 will be run in rooms A and B, workshop 2 in rooms C and D, etc. They are repeated throughout the day, so one attendee might do them in the order 15423, and another might do 42315.
There will be 45 people in each workshop. The nub of the problem is that the organisers want as much cross-pollenation as possible. People do not get to choose what order they do the workshops: they are told which room to be in at what time. The organisers would like each attendee to meet as many new people as possible in every single session.
So here’s the maths question: What is the minimum average number of repeat people that attendees have to meet in each session? By “repeat people” I mean “people they have already attended a previous session with.”
There is one extra constraint: There is one group of 30 people (labelled “FRIENDS” in the spreadsheet below) that have to be kept together in every session. So they only get 15 people in every session that they may not have met before, ie for them the min value of Repeat People is 30 in every session. This also has an impact on all the other people in the other sessions.
However this is still an interesting problem even without the extra 30-people constraint.
So in session one, Repeat People = 0. In every one of the workshops in session 1, attendees are in a brand new group of people that they have never attended this conference with before.
So what is the minimum average value of Repeat People for session 2? I’m specifying average, because it would be possible to keep things pure for at least one attendee, where they meet 44 new people in every single session. But that would have an adverse effect on everyone else. So I’m aiming for everyone to have roughly the same number of Repeat People per workshop.
I have two theories, one of which I can prove:
Apart from in Session 1, the average Repeat People is definitely greater than zero. You can’t avoid meeting attendees more than once (if you’re spreading the load evenly) (I can prove this one).
The average number of Repeat People will get gradually higher throughout the day. The first solution I came up with maintains a constant number for Repeat People after session 1, but it’s non-optimal (I think).
The problem is described here. You could approach the problem as a coding kata, which I’d love to do at some point – I didn’t have the time on this occasion. I ended up just solving it using pen and paper.
My solution is below. It won’t be the only solution, there are probably better ones out there that rely more on randomisation and less on patterns (or just use better patterns).
Don’t scroll down if you want to have a go at it yourself first!
…
…
So, I found a solution which works pretty well. I’m pretty pleased with it, and it’s nice and simple and neat.
The participants are split into groups of 15. The FRIENDS are in two groups of 15, both marked “FRIENDS” in the spreadsheet below. All the other groups are non-FRIENDS (well they might be friends, who knows? But they still don’t get to stay together – we’re mean like that).
It does mean that the people move in groups of 15, and they will stay in those groups. Not that they will necessarily know it. Because of the numbers, no matter what you do, they will keep encountering some people repeatedly (the maths of this is a separate problem which I’ve blogged about here). If you shuffle the list and assign the non-FRIENDS to 28 groups of 15, hopefully they will already be mixed up with people they don’t know, so they needn’t be aware that they have been grouped. I’ve labelled the groups B1 to O1 and B2 to O2.
What it does mean is that each group of 15 never encounters another group of 15 twice – they meet a different two groups in every session. So everybody meets 30 new people in every session (I haven’t actually proved this but I’m pretty confident).
(Since I came up with this, I’ve realised I can improve it quite a lot so that people don’t have to stay with exactly the same 15 people – scroll down to the bottom to see this improvement).
So, there are three groups in every session, like this (this is my actual solution):
Here’s how I did it:
First, split the non-FRIENDS people into two halves, 225 in each half. The first half has groups B1 to O1, and the second group has B2 to O2.
For now, we will also split the FRIENDS into two groups, A1 and A2 (this was my “Aha” moment, all made possible because of the fact that you have duplicate workshops in each session).
So for each half, we have letters A to O. For the first session, we just spread them across the 5 workshops: ABC in the workshop 1, DEF in workshop 2… etc.
For the second session, the first group in each triplet just shuffles along to the next workshop. So A is now in workshop 2, D is in workshop 3, etc.
We keep doing this all the way down the sessions, for the first group in each triplet.
For the second group in each triplet (B, E, H, K and N), instead of shuffling them on by 1, we shuffle them 2 workshops along. So, B was in workshop 1 in session 1, then we add 2 so they are workshop 3 for session 2, then add 2 again so they are in workshop 5 for session 3, keep going (wrapping around) and they are in workshop 2 for session 4 and workshop 4 for session 5. Do this for all the second groups (B, E, H, K and N).
For the third group in each triplet (C, F, I, L, O), add 3 on each time. So group C has the following workshops: 1, then 4, then 2, then 5, then 3.
Do this for all of those third groups.
This is what you get:
Now, at this point you have a problem: Your FRIENDS group have been split into two groups of 15. But ooh! Look! You did the same thing for A1 to O1 as you did for A2 to O2!
A1 and A2 are always in the same workshops at the same time. So you can move A2 into the same workshop as A1, and swap another group out into the spot left blank by A2.
I then renamed both A1 and A2 to “FRIENDS”, and that’s how I arrived at the spreadsheet pasted above.
POST SCRIPT (also see separate maths problem here):
Since I came up with this, I’ve realised I can improve it quite a lot so that people don’t have to stay with exactly the same 15 people:
The “FRIENDS” group mess it up a bit, but in most cases you’ll have parallel groups moving independently in duplicate workshops, eg when group C1 is doing workshop 3, group C2 will be doing the other duplicate of workshop 3.
Well… If each group of 15 was split into two sub groups of 7 and 8, then they could shuffle around and meet each other. Also this could be done dynamically.
So, for instance, you have C1a (7 people), C1b (8 people), C2a (7 people) and C2b (8 people).
In session 2, swap C1b and C2b so now only 7 (or 8) people stay together. Do the same with all groups (except those affected by the “FRIENDS” group).
In session 3, put C1a with C2a and C1b with C2b. This adds up to 14 and 16, so somebody will have to switch sub groups. In sessions 4 and 5 you could split them again, but this time randomly. As long as all the Cs are doing the same workshops, you can split them how you like. Ultimately they will all meet each other so they’ll still have repetition with 15 people overall, but it won’t be the same 15 people in every workshop. And they’ll still get 30 brand new people in every workshop.
I think this would make a great code kata, although I found a solution using pen and paper. It is a real problem, which my friend is genuinely trying to solve.
She is organising a conference. She has been given the following very interesting, and non-negotiable, requirements:
There will be one day of workshops. There are 5 sessions and 5 workshops. There will be 45 people in each workshop. There are 450 conference attendees, so each workshop is duplicated in each session. That is to say, during each session there will be ten actual workshops, but only five distinct workshops. So workshop 1 is happening simultaneously in two different rooms, as are the rest of them.
The aim is for participants to meet as many new people as possible. So for each attendee, we want to minimise the number of people in each workshop that they have met in a previous workshop.
We also want every attendee to attend every workshop.
And there is one more special requirement: There is a group of 30 attendees, we’ll call them FRIENDS, that must be kept together at all times. So in their workshops, there will be a rotating number of 15 extra people. They must meet a different 15 people in every workshop.
I have a solution for this, but I’ll post it separately in case you want to try it for yourself.
Here is a diagram that might help you to visualise the problem:
tl;dr: The mathematical definition of an idempotent function is subtly different to the definition used in software engineering. In software engineering an idempotent function is one that has the same impact on state, no matter how many times it is run. In mathematics, an idempotent function is one where f(x) =f(f(x)).
The concept of idempotence came up recently at work, in the context of infrastructure. A statement along the lines of “When treating infrastructure as code, it’s often important to ensure that your functionality is idempotent.”
I asked what “idempotent” meant, and I was given the (incorrect in all contexts) answer, “for the same input, you will always get the same output.” I was also told (correct for maths, but not for software) that the following function is not idempotent:
f(x) = x + 1
…but the following function is idempotent:
f(x) = x * 1
This instantly got me asking questions, because the first two definitions I was given were at odds with one another. The first definition describes a deterministic function. For instance: Both f(x) = x + 1 and f(x) = x * 1 are deterministic, ie given the same input, you’ll always get the same output (3 + 1 will always be equal to 4, and 3 * 1 will always equal 3).
But then I was given a better example, more relevant to the original conversation: If you have a function that adds an entry to a hosts file, you want to know that no matter how many times you execute that function, you will only ever add one entry to the hosts file. You don’t want to add more than one entry.
For instance, we start with a hosts file that looks like this:
127.0.0.1 localhost
We run our function, and now it looks like this:
127.0.0.1 localhost 255.255.255.255 broadcasthost
We run our function again, and nothing changes. The broadcasthost entry has already been added. Our function has nothing to do.
And then I found a true (in mathematics) definition of idempotence:
A function f(x) is idempotent if f(x) = f(f(x)).
To reiterate: The originator made a mistake: It is NOT true that idempotence is defined as “the same input always gives the same output”.
That is to say, if a function is idempotent and you apply that function to x, then you apply the function again to the return value, you still get the same result. Keep taking the result of each pass and sending it back into the function, and you still get the same result.
At this point I didn’t know about the difference between mathematical idempotence and software idempotence, and I was happy with my new definition: In our hosts file example, if our function takes the file content as an input and outputs the transformed result as an output, you can keep reapplying the function and you will keep getting the same result.
Using our new definition, we can easily see how f(x) = x + 1 is not idempotent, but f(x) = x * 1is idempotent.
A pure function is one that has no side effects and no hidden state. The example given was this one:
f(a,b) = a + b
My confusion stemmed from two sources: Firstly, how can I apply my definition above – f(x) = f(f(x)) to this new example? It takes two parameters, but only returns one result! But secondly, how can it possibly be idempotent? It’s deterministic, yes, but any way you can find of repeatedly applying the same function to a new output will surely produce a different result? And what on earth does its pureness have to do with anything??
Well. I asked a bunch of clever people, and discovered that I had been dealing with the mathematical definition of idempotence, which is subtly different to the software engineering definition.
In software engineering, it’s all about state. My hosts file example was flawed because I had assumed that the hosts file content was being passed in as an input and then returned as an output. In fact, we are talking about a function that acts on the hosts file. This function’s input may be the hosts file path. Its output may be some kind of success code. It is not a pure function, because it will have the side effect (sometimes) of altering the state of the hosts file.
BUT our idempotent hosts-file-editing function can be run several times, and its effect on state will always be the same. No matter how many times we run this function, the hosts file will always be impacted in the same way.
The article that confused me so much was in fact making a very simple point: Pure functions are idempotent because they do not alter state. Therefore state is always impacted in the same way by multiple calls to a pure function, because it is simply not impacted. So in reality, most idempotent functions are not pure, but all pure functions are idempotent.
One common example of idempotence in software engineering is the HTTP specification – which states that GET, PUT and DELETE requests should all be idempotent, but POST should not.
At this point I will quote my colleague Mouad (and the Stormpath blog), who between them say this:
“The HTTP RFC have a better definition which goes:
A request method is considered “idempotent” if the intended effect on the server of multiple identical requests with that method is the same as the effect for a single such request.
The ‘intended effect’ as defined above is not the same thing as the returned value, example: calling PUT two times may return a different result in the second call (e.g. 409 conflict), but a PUT is still idempotent if the state and effect didn’t change by the second call, in other words, ‘HTTP idempotency only applies to server state – not client state’ ref. https://stormpath.com/blog/put-or-post.”
Hopefully your head has not exploded. Or if it did, I manage to unexplode it and return it to its former state. Hopefully also, no matter how many more times you read this post, your head will remain unexploded. And we have ourselves an idempotent blog post. Voila!
I’m currently helping my 15-yr-old son revise for his maths GCSE, and one topic is “finding the nth term of a quadratic sequence”. I’m an ex high school maths teacher, but I had forgotten how to do this. I couldn’t find decent complex examples on either of my favourite GCSE maths revision sites (Maths Genie and BBC Bitesize), and when you’re doing the more complex examples, a step-by-step guide is really useful.
So I’m placing my notes here in case they’re any use to anyone else.
You’re aiming for a result of an2 + bn + c, but easier examples might have a solution of an2 + b, and even easier ones will just be an2.
Simplest Example (an2):
Find the nth term for the following quadratic sequence: 3, 12, 27, 48, …
First calculate the gaps between the numbers – these are 9, 15 and 21.
Then find the gaps between the gaps – these are 6 and 6. Like this:
Take that 6 and divide it by 2 (it’s easy to forget to divide by 2!), to get 3. This tells you that your final result will contain the term 3n2.
I’ve already told you that this is a simple example – we’ve reached our solution: 3n2. But you should always check your results:
n
1
2
3
4
n2
1
4
9
16
3n2
3
12
27
48
Yup, that’s our original sequence.
More Complex Example (an2 + b):
Find the nth term for the following quadratic sequence: 1, 10, 25, 46, …
First calculate the gaps between the numbers – these are 9, 15 and 21.
Then find the gaps between the gaps – these are 6 and 6. Like this:
Take that 6 and divide it by 2 (it’s easy to forget to divide by 2!), to get 3. This tells you that your final result will contain the term 3n2.
Create a grid, which starts with your original sequence. Below that, add whatever rows you need to help you calculate 3n2.
Now, subtract 3n2 from the original sequence. So in the below grid, we subtract the fourth row from the first row, and that gives us a new sequence, which we have placed in the fifth row:
start
1
10
25
46
n
1
2
3
4
n2
1
4
9
16
3n2
3
12
27
48
start minus 3n2
-2
-2
-2
-2
We now have a row of constant numbers. This tells us we can reach a solution. It tells us to add -2 to 3n2, and that will be our solution: 3n2 – 2.
We can easily check this by adding up the fourth and fifth rows, which gives us the first row (the original sequence).
Most Complex Example (an2 + bn + c):
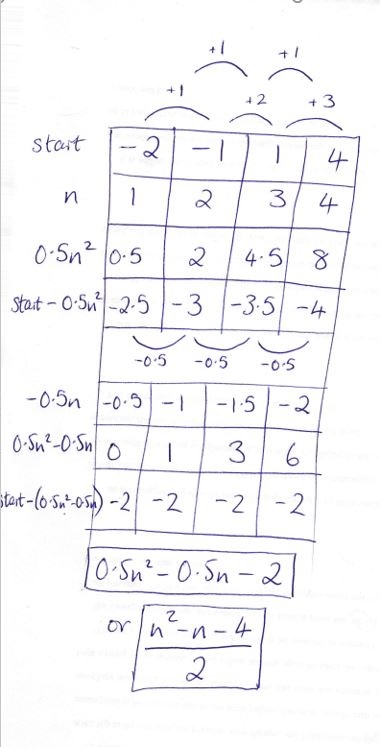
Find the nth term for the following quadratic sequence: -8, 2, 16, 34, …
First calculate the gaps between the numbers – these are 10, 14 and 18.
Then find the gaps between the gaps – these are 4 and 4. Like this:
Take that 4 and divide it by 2 (it’s easy to forget to divide by 2!), to get 2. This tells you that your final result will contain the term 2n2.
Create a grid, which starts with your original sequence. Below that, add whatever rows you need to help you calculate 2n2.
Now, subtract 2n2 from the original sequence. So in the below grid, we subtract the fourth row from the first row, and that gives us a new sequence, which we have placed in the fifth row:
start
-8
2
16
34
n
1
2
3
4
n2
1
4
9
16
2n2
2
8
18
32
start minus 2n2
-10
-6
-2
2
We don’t have a row of constant numbers yet, so we need to keep working. We need to look at the gaps between the numbers in our new sequence (in the bottom row of the table):
Now we have found a constant difference. This tells us that there will be a 4n in our answer. Note that this is because we have found a linear sequence. Note also that in the case of a linear sequence, we do NOT divide the number by 2.
So now we add some more rows to our grid. First we calculate 4n, and then we calculate 2n2 + 4n. Finally we subtract (2n2 + 4n) from our original sequence (subtract the 7th row from the first row):
start
-8
2
16
34
n
1
2
3
4
n2
1
4
9
16
2n2
2
8
18
32
start minus 2n2
-10
-6
-2
2
4n
4
8
12
16
2n2 + 4n
6
16
30
48
start minus (2n2 + 4n)
-14
-14
-14
-14
We now have a row of constant numbers. This tells us we can reach a solution. It tells us to add -14 to 2n2 + 4n, and that will be our solution: 2n2 + 4n – 14.
We can easily check this by adding up the seventh and eighth rows, which gives us the first row (the original sequence).
More worked complex examples
Note that in this next one there is a NEGATIVE difference between the terms of the sequence on row 5. This one can easily catch you out. Rather than thinking of the difference between the numbers, it helps to ask yourself, “how do I get from each term to the next one?” The answer in this case is, “subtract one”. This one can also look a little tricky because it contains fractional numbers, but you just follow the same rules as before:
Telling the Difference Between a Linear Sequence (an + b) and a Quadratic Sequence (an2 + bn + c).
When we calculate gaps between the numbers in the sequence, if the first level of gaps is constant, this means it is a linear sequence:
If the second layer of gaps is constant, it is a quadratic sequence:



















 ).
).